2020年,OpenAI的工程师们盯着屏幕上的训练日志,手心冒汗。
GPT-3已经烧了数百万美元,但没人知道它能不能用。直到有人随手输入了一个问题:
"把'我去商店'翻译成法语。"
模型回答:"Je vais au magasin."
没有微调,没有示例,它就懂了。
那一刻,房间里安静了几秒。然后有人轻声说:"它活了。"
一、2018:两个"天才少年"的诞生
2018年的NLP圈子,像是一个平静的湖面。
Google的Jacob Devlin和OpenAI的Alec Radford,两个素未谋面的研究员,几乎同时扔下了两颗炸弹。
BERT和GPT-1。

2018年,BERT和GPT-1的诞生开启了预训练时代
Devlin是个典型的Google人——严谨、务实。他的BERT像是一个"阅读理解高手":遮住句子里的几个词,让模型猜。猜多了,自然就懂语法了。
Radford则是个"叛逆者"。他的GPT-1只做一件事:预测下一个词。就像你打字时的输入法,猜你接下来想说什么。
Radford后来承认,GPT-1的论文被顶会拒了。审稿人说:"这不过是语言模型,没什么新意。"如果当时Radford放弃了,可能就没有后来的ChatGPT了。
这两个模型的参数量都只有1亿左右——按今天的标准,连"小模型"都算不上。
但它们证明了一件事:让模型先读遍互联网,再针对具体任务微调,比从头训练强十倍。
这就是"预训练+微调"范式。
产品启示:这一代模型需要为每个任务单独训练,就像雇了一个大学生,还要再培训三个月才能上岗。成本太高,只有大公司玩得起。
二、2020:那个"活了"的时刻
2020年春天,OpenAI的实验室里弥漫着咖啡和焦虑的味道。
GPT-3的训练已经进行了几个月,消耗了数千块顶级GPU。电费单上的数字让财务部门心惊肉跳——够买一辆法拉利了。
但问题是:它有用吗?
之前的模型都需要针对每个任务微调。GPT-3有1750亿参数,微调一次的成本堪比重新训练。
如果它只能做"预训练+微调",那和GPT-2有什么区别?
然后,那个翻译的测试出现了。
更惊人的还在后面。工程师们发现,只要给GPT-3几个示例,它就能理解全新任务:
输入:把中文翻译成 emoji
示例1:开心 → 😊
示例2:难过 → 😢
问题:兴奋 → ?
GPT-3回答:🤩
没人教过它"emoji翻译",它就懂了。
这种现象后来被称为上下文学习(In-context Learning)——模型从示例中"悟"出任务规则,而不是被显式训练。
💡 涌现能力:当模型规模达到某个临界点,能力会突然'跳变'。就像单个神经元只会放电,但860亿个连接起来,突然就有了意识。GPT-3的1750亿参数,在某一刻突然'觉醒'了翻译能力
涌现能力——从单个神经元到意识的质变
GPT-3的发布在AI圈引发了地震。但有趣的是,普通用户并不能直接用上它——只有API,没有对话界面。
它像一个智商200的天才,但只会自言自语,不会聊天。
三、2022:ChatGPT的"魔法"从哪来?
2022年11月30日,Sam Altman发了一条推特:
"今天我们发布了ChatGPT,试试跟它聊聊。"
没人想到,这个看似简单的"聊天机器人"会在两个月内突破1亿用户,成为史上增长最快的产品。
但ChatGPT的"魔法",其实不在GPT-3本身。
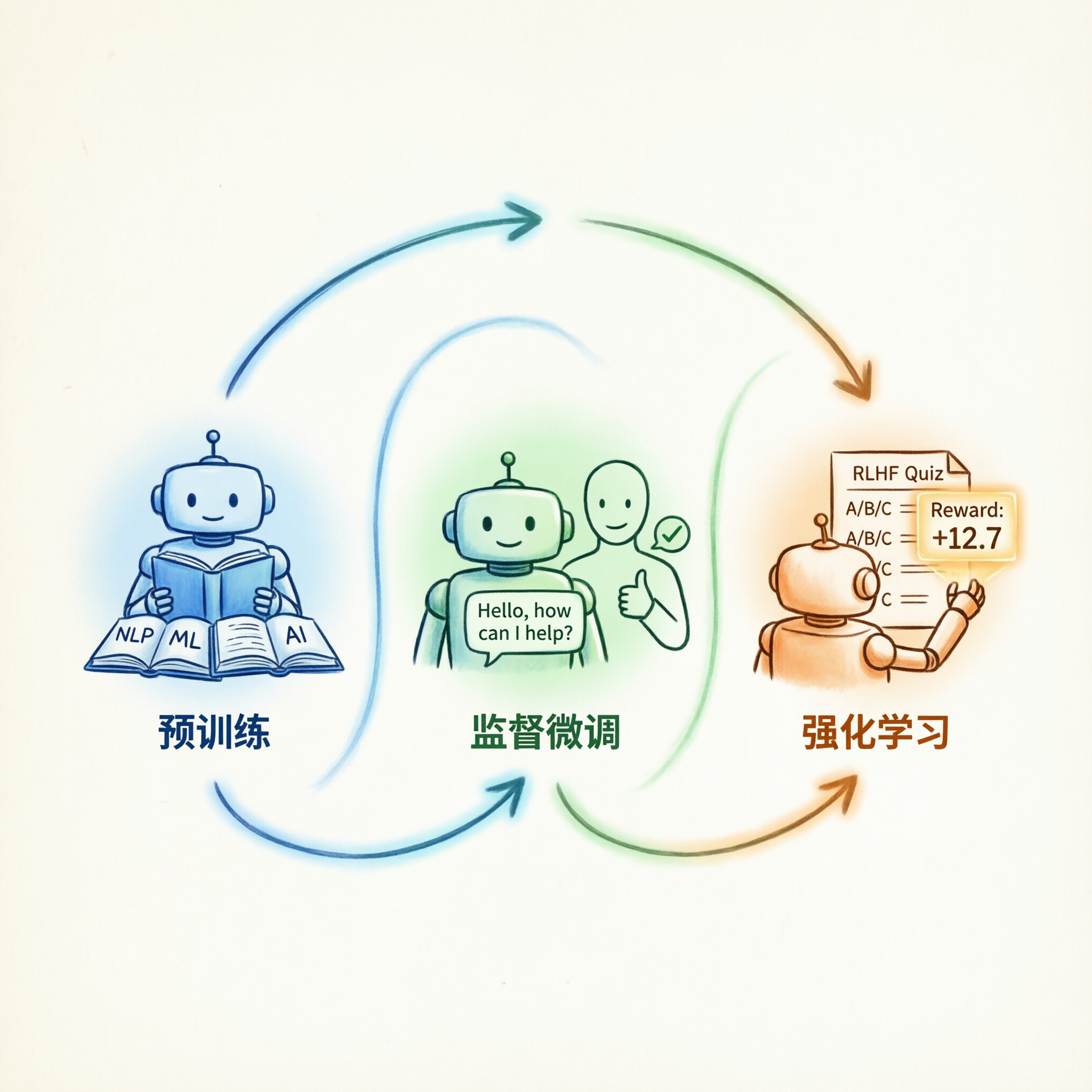
RLHF三阶段——从预训练到人类反馈强化学习
秘密武器是RLHF(人类反馈强化学习)。
简单来说,就是:
先让模型读遍互联网(预训练)
再教它"人话"——用人类写的对话示例微调(SFT)
最后让它"猜"人类喜欢什么回答,猜对了给奖励(RLHF)
🔥 幕后故事:RLHF的核心想法来自OpenAI的另一位研究员——Paul Christiano。他原本研究AI安全,担心AI会学坏。没想到这个"安全机制"成了ChatGPT的核心竞争力。
为什么RLHF这么重要?
想象一下:GPT-3像一个博览群书但不懂人情世故的书呆子。你问它"我失恋了怎么办",它可能会给你一篇学术论文式的分析,而不是一句温暖的安慰。
RLHF就是教它"什么回答让人舒服"。
产品启示:ChatGPT证明,技术能力只是基础,用户体验才是护城河。同样的GPT-3,加上对话界面和RLHF,就从"技术demo"变成了"现象级产品"。
四、2023-2024:多模态与长文本的"军备竞赛"
ChatGPT爆火后,AI圈进入了"疯狂迭代"模式。
2023年3月,GPT-4发布。它不仅能处理文本,还能看懂图片——你扔给它一张梗图,它能解释笑点在哪。
GPT-4的多模态能力——能看懂图片并解释
与此同时,Anthropic(OpenAI的"叛逃者"创办的公司)推出了Claude-2,主打长上下文——能一次处理10万token,相当于一本300页的书。
然后是Google的Gemini 1.5,直接把上下文拉到100万token,能处理整部电影的视频。
这场"军备竞赛"的核心逻辑是:
模型能力 = 推理能力 × 上下文长度 × 多模态理解
推理能力:解数学题、写代码、逻辑分析
上下文长度:能处理多长的文档/对话历史
多模态:能看懂图、听懂语音、理解视频
产品启示:这一代模型让企业级应用成为可能。RAG(检索增强生成)、代码助手、文档分析等产品形态爆发。产品经理的核心问题变成:如何把长上下文能力转化为用户价值?
五、2024-2025:DeepSeek的"逆袭"与推理革命
2024年9月,OpenAI发布了o1模型。
它的特点是"慢思考"——面对复杂问题,它会 internally 生成多个思路,评估哪个最好,再给出答案。
数学竞赛题?它能拿金牌。编程难题?它能解。
但问题是:太贵了。API价格是GPT-4的10倍。
然后,2025年1月,一个中国团队扔下了一颗炸弹。
DeepSeek-R1。

DeepSeek-R1的突破——纯强化学习驱动,无需人工标注
它的效果接近o1,但:
开源:MIT协议,随便用
便宜:API价格是o1的1/10
训练成本低:只用了600万美元,是o1的零头
更惊人的是它的训练方法。
传统方法需要大量人工标注的"思维链"数据——雇人写解题步骤,贵且慢。DeepSeek-R1直接用纯强化学习:给模型一个问题,让它自己尝试,做对了给奖励,做错了给惩罚。
模型自己"悟"出了思考的方法。
🔥 技术哲学:DeepSeek-R1证明,推理能力可以通过试错自主学习,不需要人类手把手教。这有点像AlphaGo——没人教它怎么下围棋,它自己跟自己下,下成了世界冠军。
产品启示:2025年的AI产品必须考虑"混合策略"——简单问题用轻量模型,复杂问题用推理模型。成本与效果的权衡成为核心设计决策。
六、2026前瞻:Agent原生时代
如果你以为"能推理"就是终点,那可能低估了这场革命的深度。
2025-2026年的关键词是Agent原生。

Agent原生架构——从"回答问题"到"完成任务"
传统模型的工作流程是:
用户提问 → 模型生成回答 → 结束
Agent原生模型的工作流程是:
用户给目标 → 模型自主规划 → 调用工具 → 执行 → 验证 → 完成
OpenAI的Operator、Claude 4、Google的Project Astra……这些新产品不再只是"聊天",而是能自主完成任务的代理。
你想订机票?告诉它日期和目的地,它会自己打开网站、搜索航班、比价、填写信息、完成支付。
你想分析一份财报?它会自己下载PDF、提取数据、生成图表、撰写分析报告。
这不仅是技术进步,更是交互范式的革命。
💡 从"对话式"到"代理式":用户不再与AI对话,而是委托AI完成任务。产品经理需要重新设计交互——从"输入-输出"到"目标-结果"。
七、六代模型,一条主线
回顾这八年,大模型经历了六代进化:

六代大模型演进时间线
但贯穿始终的,是一条主线:
让AI从"鹦鹉学舌"到"真正理解",再到"自主行动"。
每一代突破,都是向"人类智能"更近一步。
八、迁移思考:技术演进的启示
大模型的进化史,不仅是技术史,更是一部"Scaling Law"的胜利史。
什么是Scaling Law?简单说:规模带来质变。
数据规模:从读几百万页到读整个互联网
模型规模:从1亿参数到1750亿参数
计算规模:从几块GPU到数千块顶级芯片
但规模不是唯一答案。
DeepSeek-R1证明,算法创新可以打破算力垄断。600万美元的训练成本,效果媲美耗资数亿的o1。
这对我们有什么启示?
分层思维:复杂系统的能力往往来自简单单元的层级组合(从神经元到层,从层到模型,从模型到Agent)
涌现思维:不要只优化局部,有时候需要把系统做大,等待质变
成本思维:技术产品化的核心,永远是成本与效果的权衡
九、写在最后
2020年那个"它活了"的时刻,其实是个误会。
GPT-3并没有"活",它只是学会了统计规律,学会了模式匹配。它不理解"翻译"是什么意思,只是见过太多"中文→法文"的示例。
但2025年的R1,可能真的在"思考"。
当你看到它为了解一道数学题, internally 尝试了十几种方法,排除了错误路径,最终找到正确答案——这个过程,和人类解题已经没什么区别。
💡 1750亿参数,敌不过一个3岁小孩。但加上强化学习,它可能正在学会"思考"。
所以下次当你用ChatGPT写文案、用DeepSeek解数学题、或者用Operator订机票时,不妨想一想:
你正在见证的,是人类历史上第一次,机器学会了"深思熟虑"。
而这,才刚刚开始。